
History[edit]
The first RBMT systems were developed in the early 1970s. The most important steps of this evolution were the emergence of the following RBMT systems:
Today, other common RBMT systems include:
Types of RBMT[edit]
There are three different types of rule-based machine translation systems:
- Direct Systems (Dictionary Based Machine Translation) map input to output with basic rules.
- Transfer RBMT Systems (Transfer Based Machine Translation) employ morphological and syntactical analysis.
- Interlingual RBMT Systems (Interlingua) use an abstract meaning.
Basic principles[edit]
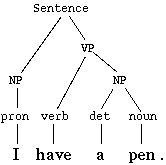
The main approach of RBMT systems is based on linking the structure of the given input sentence with the structure of the demanded output sentence, necessarily preserving their unique meaning. The following example can illustrate the general frame of RBMT:
A girl eats an apple. Source Language = English; Demanded Target Language = GermanMinimally, to get a German translation of this English sentence one needs:
- A dictionary that will map each English word to an appropriate German word.
- Rules representing regular English sentence structure.
- Rules representing regular German sentence structure.
And finally, we need rules according to which one can relate these two structures together.
Accordingly we can state the following stages of translation:
1st: getting basic part-of-speech information of each source word: a = indef.article; girl = noun; eats = verb; an = indef.article; apple = noun 2nd: getting syntactic information about the verb “to eat”: NP-eat-NP; here: eat – Present Simple, 3rd Person Singular, Active Voice 3rd: parsing the source sentence: (NP an apple) = the object of eatOften only partial parsing is sufficient to get to the syntactic structure of the source sentence and to map it onto the structure of the target sentence.
4th: translate English words into German a (category = indef.article) => ein (category = indef.article) girl (category = noun) => Mädchen (category = noun) eat (category = verb) => essen (category = verb) an (category = indef. article) => ein (category = indef.article) apple (category = noun) => Apfel (category = noun) 5th: Mapping dictionary entries into appropriate inflected forms (final generation): A girl eats an apple. => Ein Mädchen isst einen Apfel.Components[edit]
The RBMT system contains:
- a SL morphological analyser - analyses a source language word and provides the morphological information;
- a SL parser - is a syntax analyser which analyses source language sentences;
- a translator - used to translate a source language word into the target language;
- a TL morphological generator - works as a generator of appropriate target language words for the given grammatica information;
- a TL parser - works as a composer of suitable target language sentences;
- Several dictionaries - more specifically a minimum of three dictionaries:
The RBMT system makes use of the following:
- a Source Grammar for the input language which builds syntactic constructions from input sentences;
- a Source Lexicon which captures all of the allowable vocabulary in the domain;
- Source Mapping Rules which indicate how syntactic heads and grammatical functions in the source language are mapped onto domain concepts and semantic roles in the interlingua;
- a Domain Model/Ontology which defines the classes of domain concepts and restricts the fillers of semantic roles for each class;
- Target Mapping Rules which indicate how domain concepts and semantic roles in the interlingua are mapped onto syntactic heads and grammatical functions in the target language;
- a Target Lexicon which contains appropriate target lexemes for each domain concept;
- a Target Grammar for the target language which realizes target syntactic constructions as linearized output sentences.
Advantages[edit]
- No bilingual texts are required. This makes it possible to create translation systems for languages that have no texts in common, or even no digitized data whatsoever.
- Domain independent. Rules are usually written in a domain independent manner, so the vast majority of rules will "just work" in every domain, and only a few specific cases per domain may need rules written for them.
- No quality ceiling. Every error can be corrected with a targeted rule, even if the trigger case is extremely rare. This is in contrast to statistical systems where infrequent forms will be washed away by default.
- Total control. Because all rules are hand-written, you can easily debug a rule based system to see exactly where a given error enters the system, and why.
- Reusability. Because RBMT systems are generally built from a strong source language analysis that is fed to a transfer step and target language generator, the source language analysis and target language generation parts can be shared between multiple translation systems, requiring only the transfer step to be specialized. Additionally, source language analysis for one language can be reused to bootstrap a closely related language analysis.
MORE TRANSLATION VIDEO



INTERESTING FACTS
-
 Machine translation, sometimes referred to by the abbreviation MT (not to be confused with computer-aided translation, machine-aided human translation MAHT and interactive translation) is a sub-field of computational linguistics that investigates the use of software...
Machine translation, sometimes referred to by the abbreviation MT (not to be confused with computer-aided translation, machine-aided human translation MAHT and interactive translation) is a sub-field of computational linguistics that investigates the use of software...
-
Transfer-based machine translation is a type of machine translation. It is based on the idea of interlingua and is currently one of the most widely used methods of machine translation
Both transfer-based and interlingua-based machine translation have the same idea... -
Synchronous context-free grammars (SynCFG or SCFG; not to be confused with stochastic CFGs) constitute a formal model of natural language syntax, developed in the area of statistical machine translation (MT).
The theory of SynCFGs borrows from syntax-directed...
Share this Post
latest post
-
 Interpreter translation June 19, 2026
Interpreter translation June 19, 2026 -
 Translation Machines February 21, 2016
Translation Machines February 21, 2016 -
 TRANSLATION words June 1, 2016
TRANSLATION words June 1, 2016 -
 Example of old English words April 3, 2015
Example of old English words April 3, 2015 -
 Egyptian Pharaoh Ramses June 2, 2024
Egyptian Pharaoh Ramses June 2, 2024 -
 Words with old June 29, 2015
Words with old June 29, 2015 -
 English translation of Hamlet May 9, 2015
English translation of Hamlet May 9, 2015 -
 Translation Technology April 2, 2014
Translation Technology April 2, 2014 -
 Macbeth explanation September 24, 2015
Macbeth explanation September 24, 2015